
“什么是分布式系统?这取决于看系统的角度。对于坐在键盘前使用IBM个人电脑的人来说,电脑不是一个分布式的系统。但对于在电脑主板上趴着的虫子来说,这台电脑就是一个分布式系统。” —— Leslie Lamport
引言
分布式一致性问题随处可见,任何一个实体/联接模型,都可能存在分布式一致性问题。如果把单机拆开来看,CPU、内存、I/O设备组成的机箱本身就是一个小型的分布式系统,需要确保对这个系统操作的最终一致性。幸运的是这部分工作已经交给操作系统和数据库软件来帮我们完成。而在大型分布式企业级应用中,分布式最终一致性方案需要根据系统自身特点量身定制,是系统设计的重点。近年来随着沪江业务的快速增长和微服务治理推广,本地ACID事务早已不能满足业务和系统的发展需求。大部分业务流程都需要跨多微服务的调用来协作完成,并且要求系统确保分布式最终一致性。
可以选择分布式事务框架方案,目前主流的分布式事务框架大致可分为3类实现 :
-
基于XA协议的两阶段提交(2PC)方案
-
基于支付宝最早提出的TCC(Try、Confirm、Cancel)方案
-
基于ebay最早提出的消息队列异步确保方案
此外还有较轻的解决方案,业务系统可以根据自身需要,选择通过幂等/重试、状态机、恢复日志、异步校验等技术来确保最终一致性。
重型武器
采用分布式事务框架的方案,最终一致性由分布式事务框架保证,业务程序员对框架细节完全透明。选择这种方案,需要注意几个点。首先,由于分阶段提交协议本身的脆弱性,主流分阶段提交协议如2PC,3PC, TCC都无法完全确保最终一致性,要采用异步校验的手段兜底。其次,分阶段提交协议带来的高延迟,多次协议通信RTT带来的时间损耗。第三,基于消息队列异步确保的分布式事务框架实现,需要考虑消息可靠性和业务侵入问题。分布式事务框架也有巨大的优势,首先,分布式事务被框架封装成切面,业务开发只需关心纯业务。其次,分布式事务的代码开发量大大减少。对一致性和代码质量有极高要求的银行、金融领域,分布式事务框架是最佳选择。
轻型武器
不同于采用分布式事务框架的最终一致性方案,程序员也可以选择通过幂等/重试、状态机、恢复日志、异步校验等技术来确保最终一致性。这种方案不受限于平台和框架,系统较精简灵活,初期业务系统大都基于这种分布式一致性解决方案。不过这种方案对业务开发的要求更高,分布式一致性逻辑要业务程序员代码实现,容易出现bug。
其实,主流的分布式事务框架也是通过这些基本的系统机制如幂等/重试、状态机、恢复日志、异步校验等来确保的最终一致性,对比两种方案,下文主要围绕后一种展开论述,讨论5点使系统达成分布式最终一致性的技术实践。
原则
1、CAP定理

如下三属性,任何一个联网的共享数据系统最多只能同时满足 2 个 :
-
一致性(Consistency) : 每次读取都会收到最新的写入或错误
-
可用性(Availability) : 每个请求都会收到一个不是错误的响应
-
分区容忍性(Partition tolerance) : 节点之间的网络丢弃(或延迟)了任意数量的消息,系统仍继续运行
由于分区容忍性是可伸缩的最基本要求,放弃分区容忍性等于放弃可伸缩,所以分区容忍性是必选项,大部分的分布式系统都是在C和A之间做选择。需要注意的是,虽然C都叫一致性,但CAP定理中的C和数据库事务ACID中的C是完全不同的两个定义。
2、BASE原则
-
Basically Available : 基本可用
-
Soft state : 软状态
-
Eventual consistency : 最终一致性
BASE原则发展自CAP定理,舍弃了系统的强一致性而选择AP,但每个应用可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。用较通俗的话来描述就是 : “过程宽松,结果严格,你的老板不关心过程,只看结果”。NoSQL数据库Cassandra就是遵循的BASE原则设计。不过也有分布式系统设计不是遵循BASE原则,而是选择CAP中的CP,如HBase。当然,系统对CAP三者的取舍并不是一成不变,可以根据实际需要改变策略。
实践
1、重试
重试机制可以使分布式不一致数据自动恢复,前提是重试接口要提供幂等保证。重试机制是达成分布式最终一致性的重要手段。例如,超时重传是TCP协议保证数据可靠性的一个重要机制,核心思想其实就是重试。在此我向大家推荐一个架构学习交流裙。交流学习裙号:687810532,里面会分享一些资深架构师录制的视频录像
-
同步重试 : 在上次请求失败或超时,程序再次发起同步调用请求。后端程序不推荐同步重试,其一因为同步等待占用系统线程资源,其二因为重试引起的流量放大,可能导致系统雪崩。
-
异步重试 : 通过异步系统(消息队列或调度中间件)对失败或超时请求再次发起调用。推荐这种方式的重试,重试的时间间隔可以设置为根据重试次数指数增长,超过重试阈值仍未成功,可以报警通知并由人工订正。
重试也是提高系统可用性的一种有效手段。如果一个服务的可用性为98%(有1个9),1次重试之后其可用性可达到99.96%(3个9),2次重试可以达到99.9992%(5个9)。
2、幂等
幂等的数学定义为
用通俗的话来说就是 : 相同的操作执行多次 和 执行一次产生的效果是一样的。有的操作是天然幂等的,如查询、删除操作。有的操作是人为使其幂等,例如TCP的超时重传操作就是幂等的,无论客户端将一个seq字节传送多少次,服务端窗口只会用一次该字节。幂等实现方式有很多 :
-
基于记录的悲观锁,MySQL中通过SELECT FOR UPDATE语句实现。这种实现方式要设置AUTOCOMMIT=0,加锁和更新记录在同一个事务中,长时间锁定记录会降低系统的TPS,高并发场景不推荐使用。
-
基于记录版本号或状态机的乐观锁方案,适用于更新数据场景。例如,用户下单购买一个商品的扣库存操作实现幂等,可以用如下SQL语句实现 : UPDATE stocktable SET stock = stock - 1, version = version + 1 WHERE product_id = 123 and version = 1
-
基于数据库唯一索引的去重表,适用于插入和更新数据的场景,由数据库惟一索引确保多次插入和更新操作只有一次生效。
-
基于全局唯一标识token实现,这种方案要注意几点 : 1、这里校验token是否可使用 和 置token为已使用,是一个CAS原子操作,需要确保在一个原子操作中。 2、如果token存储使用的是Redis,那么验证token的CAS操作可以使用原子自增操作incr,如果Redis值大于1则token不可使用,反之可使用。还有一种实现方式是token生成系统将token预先写入Redis,用删除操作来校验token是否被使用,删除成功代表token未被使用可执行操作。 3、如果token存储使用的是MySQL,根据token分库分表和建惟一索引,同时通过insert语句来判断token是否存在,如果insert失败则token不可使用,反之可使用。
3、状态机
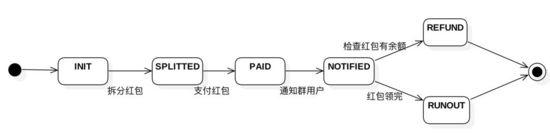
状态机是表示实体的状态根据条件转移的数学模型。通过状态机模型,系统可以判断当前不一致状态,以及如何校正不一致状态到一致状态。这样说可能比较抽象,我们拿发微信群红包的例子来说明。当你点开发红包按钮,输入总金额、红包个数、标题,点击支付成功后。其实根据时间先后红包系统后台至少经历过这样一个状态机 :
-
1、当输入总金额、红包个数、标题点击提交,首先后台创建一个初始化状态(INIT)红包
-
2、接着系统将根据你输入的总金额和个数n将红包拆分成n分,此时红包的状态为拆分成功(SPLITTED)
-
3、此时红包后台会监听异步支付消息,如果支付成功则将红包置为支付成功(PAID)
-
4、之后红包系统会通知微信IM系统,发送消息通知群里的用户,此时红包状态为(NOTIFIED)
-
5.1、群里的用户把红包抢光了,红包状态被系统置为已抢光(RUNOUT)
-
5.2、还有一种可能,如果群里都是程序员,忙着撸代码,没时间抢红包,一定时间后红包自动退款到支付账号,红包状态便为(REFUND)
这只是一个正常业务流程的红包状态机,异常情况如拆分失败、支付失败、通知失败、退款失败等情况也同理存在一个状态机器。为了方便业务实体状态回滚和校正,状态机要尽量设计精简,转移到下一个状态的边尽可能的只有一条路径(终结状态会例外),这样在回滚和校正时能够明确前一个状态和后一个状态。举个例子,如果系统发现红包一直处于PAID状态,而并没有流转到NOTIFIED状态,能够判断是通知群用户出现异常,可以根据实际情况重新通知群用户或者将超期红包退款。
4、恢复日志
恢复日志是程序现场的记录,也是业务数据恢复的重要依据。恢复日志log要求全局唯一的requestId来标示请求(实际的业务场景可采用不会重复有含义的业务id),出现异常,可以根据requestId维度redo和undo业务操作,恢复日志具体可分为三部分 :
-
requestId请求开始时,记录REQUEST START requestId
-
本地修改时,记录全部的(requestId,x,originalValue, destValue)四元组,x代表操作对象,修改前x的值为originalValue,本次修改的目的操作值为destValue
-
requestId结束时,记录REQUEST End requestId
恢复日志是系统从不一致的状态恢复到一致状态的重要数据,丢失恢复日志,意味着不一致可能无法恢复。为什么是可能,因为有时可以通过状态机对不一致的状态进行恢复。
5、异步校验
彻底解决分布式一致性问题,有著名的Paxos算法,通过该算法分布式系统自发达成一致性。而在具体的业务场景,完全不需要系统自发的达成共识,我们只要在业务系统外部加上严格的业务约束,用来仲裁业务系统的状态。通过异步校验,可以发现分布式系统中的异常状态,并通过恢复日志进行脚本批量恢复或者人工处理恢复,根据校验的粒度有 :
-
根据业务实体id校验,使用消息队列,将需要校验业务id投递给校验系统,进行异步校验。
-
根据时间维度批量校验,使用异步调度框架,根据时间粒度批量获取进行异步校验。
此外,并不是所有系统都有可靠消息队列和调度服务支撑,业务系统可以增加一个本地业务id校验回执字段,校验系统根据校验步骤回调设置校验回执字段,并对校验未通过的数据进行重校验或者订正。
总结
分布式最终一致性问题,后端程序员在实际开发中经常遇到。在实际系统开发中为了确保最终一致性,往往需要组合多个技术点打出组合拳,因为招数是死的,程序员是活的。总结上面提到的技术点,我们可以通过幂等和重试机制,使得不一致数据能够自动恢复;通过异步校验机制发现业务系统的不一致数据;通过状态机和恢复日志,纠正不一致的业务数据。最后,感谢阅读本文,欢迎留言讨论。在此我向大家推荐一个架构学习交流裙。交流学习裙号:687810532,里面会分享一些资深架构师录制的视频录像